|
|
|
 www.design-reuse-embedded.com
www.design-reuse-embedded.com |
|

FPGA 在加速下一代深度学习方面能击败GPU吗?
Cadence Tensilica 社区, Jun. 01, 2017 – FPGA 在加速下一代深度学习方面能击败GPU吗?
许多图像、视频和语音来自社交媒体和物联网等数据源,这些内容的数字数据继续急剧增长,从而促使企业界需要分析技术让这些数据易于理解、具有实用性。
数据分析常常依赖机器学习算法。在诸多机器学习算法中,深度卷积神经网络(DNN)为重要的图像分类任务提供了最高的准确度,因而得到了广泛采用。
在最近的现场可编程门阵列国际研讨会(ISFPGA)上,来自英特尔加速器架构实验室(AAL)的埃里科.努维塔蒂(Eriko Nurvitadhi)博士介绍了一篇研究论文,题为《FPGA 在加速下一代深度学习方面能击败GPU吗?》(http://dl.acm.org/citation.cfm?id=3021740)。他们的研究以最新的高性能英伟达Titan X Pascal 图形处理单元(GPU)为参照,评估了新兴的DNN算法在两代英特尔FPGA(英特尔Arria10和英特尔Stratix 10)上的表现。
英特尔可编程解决方案部门的FPGA 架构师兰迪.黄(Randy Huang)博士是这篇论文的合著者之一,他说:"深度学习是人工智能方面最激动人心的领域,因为我们已经看到深度学习带来了最大的进步和最广泛的应用。虽然人工智能和DNN 研究倾向于使用 GPU,但我们发现应用领域与英特尔的下一代FPGA 架构之间是完美契合的。我们考察了即将出现的FPGA 技术进展,以及DNN算法加快步伐的创新,还考虑了对于下一代 DNN而言,未来的高性能FPGA是否比GPU更胜一筹。我们的研究发现,FPGA 在DNN 研究中表现很出色,可以运用于需要分析大量数据的人工智能、大数据或机器学习等研究领域。使用经过精简或紧凑的数据类型vs标准的32位浮点数据(FP32)时,接受测试的英特尔Stratix10 FPGA其性能胜过GPU。除了性能外,FPGA还很强大,就是由于它们具有适应性,很容易实现变化的部分,只需要重复使用现有的芯片,让团队在短短6个月内就可以完成从提出想法到构建原型的过程,而不是花18个月构建专用集成电路(ASIC)。"
测试中使用的神经网络机器学习
神经网络可以用加权边(weighted edge)互连的神经元图形来系统地表述。每个神经元和边分别与激活值和权重关联起来。该图由多层神经元组成。一个例子。
神经网络计算会通过网络中的每个层。就某个特定的层而言,每个神经元的值通过相乘和累加上一层的神经元值和边权重来计算。计算高度依赖相乘-累加操作。DNN计算包括正向传递(forward pass)和反向传递(backward pass)。正向传递在输入层采样,然后通过所有隐藏层,并在输出层生成预测。至于推理,只需要正向传递来获得某个特定样本的预测。至于训练,来自正向传递的预测错误随后在反向传递过程中被反馈回来,以更新网络权重――这被称为反向传播算法(back-propagation algorithm)。迭代训练进行正向传递和反向传递以调整网络权重,直至达到期望的准确度。
几个变化让FPGA成为一种可行的替代方案
硬件:虽然FPGA与高端GPU 相比具有卓越的能效(性能/瓦特),但它们并不以提高极高的峰值浮点性能出名。FPGA技术正在迅速发展。即将推出的英特尔Stratix10 FPGA性能强大:提供5000多个加固的浮点单元(DSP),超过28MB的芯片上内存(M20Ks),与高带宽内存(多达4x250GB/s/stack或1TB/s)集成,并借助新的HyperFlex技术提高了频率。英特尔FPGA 提供了一个全面的软件生态系统,涵盖范围甚广:有低级的硬件描述(Hardware Description)语言,也有OpenCL、C和C++的较高级软件开发环境。英特尔会进一步将FPGA与英特尔的机器学习生态系统和传统框架(比如近日提供的Caffe),以及很快就会推出的其他框架结合起来,充分利用MKL-DNN库。基于14nm英特尔技术的英特尔Stratix10在FP32吞吐量方面峰值性能达到9.2TFLOP/s。相比之下,最新的Titan X Pascal GPU在FP32吞吐量方面的性能为11TFLOP/s。
新兴的DNN算法:更深层的网络提高了准确度,但大大增加了参数数量和模型大小。这增加了计算带宽、内存带宽和存储要求。正因为如此,使用更高效的DNN已成了趋势。一股新兴的趋势是,采用远低于32位的紧凑型低精度数据类型。16位和8位这两种类型的数据成为新的常态,因为它们得到了DNN软件框架(比如TensorFlow)的支持。此外,研究人员针对精度极低的2位三进制DNN和1位二进制 DNN 继续提高准确度,其中值分别受限于(0,+ 1,-1)或(+ 1,-1)。努维塔蒂博士最近合著的一篇论文首次证明:三进制DNN可以为知名的ImageNet数据集获得最先进的(即ResNet)准确度。另一个新兴趋势是,通过精简、ReLU 和三进制化(ternarization)等技术,在DNN神经元和权重中引入稀疏性(一个个零的存在),这可以让DNN拥有50%左右至90%左右的零。由于没必要针对这类零值进行计算,如果执行这类稀疏DNN 的硬件可以有效地略过零计算,那样可以提升性能。
新兴的低精度、稀疏DNN算法在算法效率上比传统的密集FP32 DNN高出几个数量级,但它们引入了GPU难以处理的不规则并行性(irregularparallelism)和自定义数据类型。相比之下,FPGA是为极高的可定制性设计的,它在运行不规则并行性和自定义数据类型时表现出色。这类趋势使未来的FPGA成为一种切实可行的平台,可用于运行DNN、人工智能和机器学习等应用。黄说:"专门针对FPGA的机器学习算法有更大的预留空间。"图2表明了FPGA极高的可定制性(2A),因而能够有效地实施新兴的DNN(2B)。
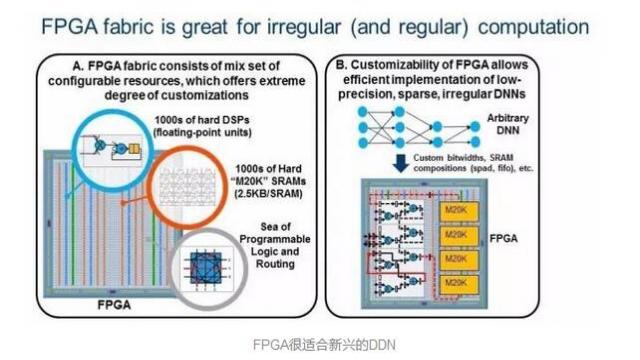
FPGA很适合新兴的DDN
研究所用的硬件和方法

GPU:使用已知的库(cuBLAS)或框架(Torch with cuDNN)
FPGA:使用Quartus Early Beta版本和PowerPlay来估计
短阵相乘(GEMM)测试的结果。GEMM是DNN中的关键操作。(图片来源:英特尔)
研究1:矩阵相乘(GEMM)测试
DNN 高度依赖矩阵相乘运算(GEMM)。常规DNN依赖FP32密集GEMM。然而,较低精度、稀疏的新兴DNN 依赖低精度及/或稀疏的GEMM。英特尔团队评估了这些不同的GEMM。
FP32 密集GEMM:由于FP32密集GEMM已得到充分的研究,英特尔团队比较了FPGA和GPU数据表上的峰值数字。TitanX Pascal 的峰值理论性能对Stratix 10而言分别是11 TFLOP和9.2 TFLOP。图3A显示,相比英特尔Arria10,DSP 数量多得多的英特尔Stratix 10 提供了大大提升的FP32性能,让Stratix10的性能足够接近Titan X 的性能。
低精度INT6 GEMM:为了表明FPGA在可定制性方面的优点,该团队将四个int6封装到一个DSP模块中,以研究FPGA的6位(Int6)GEMM。至于本身不支持Int6 的GPU,他们使用了峰值Int8GPU性能来进行比较。图3B显示,英特尔Stratix 10 的性能优于GPU。FPGA的性能/瓦特比GPU还要来得吸引人。
精度非常低的1位二值化GEMM:最近的二值化DNN 提议使用极其紧凑的1位数据类型,因而可以用非常适合FPGA的同或(xnor)和位计数(bitcounting)操作取代相乘操作。图3C显示了团队的二进制GEMM测试结果,其中FPGA 的性能比GPU高得多(即针对不同的频率目标,性能高出2倍左右到10倍左右)。
稀疏GEMM:新兴的稀疏DNN包含许多零。该团队针对85%零值的矩阵测试了稀疏的GEMM(基于经过精简的AlexNet而选择)。该团队测试的一种GEMM设计利用FPGA的灵活性,以一种细粒度的方式跳过零计算。该团队还在 GPU上测试了稀疏的 GEMM,但发现性能不如在GPU上执行密集的GEMM(矩阵一样大小)。该团队的稀疏GEMM测试(图3D)显示,FPGA的性能比GPU更胜一筹,具体取决于FPGA的目标频率。
DNN准确度的趋势以及FPGA和GPU在三进制ResNet DNN上的测试结果。(图片来源:英特尔)
研究2:使用三进制ResNet DNN测试
三进制DNN最近提议将神经网络权重限制于+1、0或-1。这允许稀疏的2位权重,并用符号位操作取代相乘。在这个测试中,该团队使用了一种为零跳跃、2位权重定制的FPGA设计,没有以最佳方式运行Ternary-ResNetDNN的乘法器。
不像其他许多低精度、稀疏的DNN,三进制DNN提供了与最先进的DNN(即ResNet)相当的准确度,如图4A所示。努维塔蒂说:"许多现有的GPU和FPGA研究仅针对基于AlexNet(2012年提议)的ImageNet方面'足够好'的准确度。最先进的Resnet(2015年提议)提供了比AlexNet高出10%以上的准确度。2016年年底,在另一篇论文中,我们率先表明,Resnet上低精度、稀疏的三进制版本DNN 算法获得的准确度与全精度ResNet只相差1%左右。这个三进制ResNet是我们在FPGA研究中的目标。因此,我们率先表明,FPGA可提供同类中最佳的(ResNet)ImageNet准确度,它能够比GPU更好地实现这一点。"图4B显示了英特尔Stratix 10 FPGA和Titan X GPU在 ResNet-50上的性能和性能/瓦特比。即使性能方面保守估计,英特尔Stratix 10 FPGA也已经比TitanX GPU的性能高出60%左右。如果是适中的估计和大胆的估计,结果更显著(即提升2.1倍和3.5倍)。值得关注的是,按大胆估计,英特尔Stratix 10 750MHz的性能可以比TitanX的理论峰值性能高出35%。就性能/瓦特而言,无论保守估计还是大胆估计,英特尔Stratix 10的性能都要比Titan X高出2.3倍到4.3倍。
FPGA在研究测试中表现如何
结果表明,就稀疏的DDN、Int6 DDN和二值化DDN而言,英特尔Stratix10 FPGA的性能(TOP /秒)比Titan X Pascal GPU分别高出10%、50%和5.4倍。在三进制ResNet上,Stratix 10 FPGA的性能比Titan X Pascal GPU高出60%,而性能/瓦特高出2.3倍。结果表明,FPGA有望成为加速下一代DNN 的首选平台。
FPGA在深层神经网络中的未来
FPGA能否在下一代 DNN的性能上击败GPU?英特尔在两代FPGA(英特尔Arria10和英特尔Stratix 10)以及最新的Titan X GPU上评估了各种新兴的DNN,结果表明,目前DNN算法方面的趋势可能有利于FPGA,FPGA甚至有望提供卓越的性能。虽然本文描述的结果来自2016年完成的研究工作,但英特尔团队继续针对现代DNN算法和优化(比如FFT / winograd 数学变换、大胆的量化和压缩)来测试英特尔FPGA。该团队还指出,除了DNN外,FPGA在其他不规则应用以及对延迟敏感的应用(比如ADAS和工业用途)等领域也有机会。
黄说:"目前使用32位密集矩阵乘法方面的机器学习问题正是GPU擅长处理的。我们鼓励其他开发人员和研究人员与我们一起努力,再次系统地阐述机器学习问题,以便充分发挥使用较短位处理技术的FPGA 具有的优势,因为FPGA 可以适应向低精度的转变。"
 Contact Us
Contact Us